 Computers
are truly amazing machines. They
are marvels of the modern age. They
in fact make the modern age what it is. Without
computers we would
Computers
are truly amazing machines. They
are marvels of the modern age. They
in fact make the modern age what it is. Without
computers we would
Computers
And
The
Theory of Evolution
Sean
D. Pitman M.D.
© July 2003
|
|
Computers
are truly amazing machines. They
are marvels of the modern age. They
in fact make the modern age what it is. Without
computers we would
The power of computers rests in their ability to process information for us. The faster they do this, the faster we can solve problems and arrive at solutions. Computers have improved over the years and are now so fast that problems and calculations that used to take many years can be solved in fractions of a second. Because of their amazing success in problem solving, computers have been integrated into practically every aspect of our lives. Scientists have especially turned to the computer as a tool to investigate the natural world. In fact, many feel like the computer can simulate nature itself, even life itself. Scientists have created computer programs that apparently show how life grows, competes, changes, and of course, evolves. The computer itself has even been compared to a living creature. Many feel that someday computers will arrive at a point of human-like intelligence and self-awareness. A world of intelligent silicon-based creatures will co-exist with carbon-based creatures, both growing and evolving together. Some suggest that computer human hybrids will also develop.
This is the stuff of science fiction of course, but many times the science fiction of the past is the reality of today. Discovering the very language of life has been a human dream for centuries, and now it is here. Today we humans are manipulating the very language that defines our own existence. The coded language of DNA has been cracked and great strides have been made in reading, understanding, and even manipulating what this language says and how it is then expressed in living things - even ourselves. In a similar way, humans create and then manipulate the coded languages of computers. The similarities between computer language and the language of life are striking. If the language of living things could be fully understood, it seems reasonable that it could eventually be programmed into computer code. An immortal computer "copy" of it could be created and given an existence in either a computer animated world or a bio-robotic world. For example, a human might one day exist, with all human functions, thoughts, feelings, and physical needs, in computer code and animation (much like the movie, "The Matrix"). How might this be possible?
 Computer
function is based on a coded language written using an alphabet of only two
letters called "zero" and "one."
The
function of living things is also based on a coded language written using a
chemical alphabet of only four letters labeled "A, T, G, and C."
Already the similarity between computers and living things is striking.
Everything that we are is written down in a book of sorts.
The
writing of this book employs a real alphabet and a real language.
So far, the only difference between the genetic code of humans and the
binary code of computers is the difference in the number of letters used.
We have four letters while computers have only two letters
Computer
function is based on a coded language written using an alphabet of only two
letters called "zero" and "one."
The
function of living things is also based on a coded language written using a
chemical alphabet of only four letters labeled "A, T, G, and C."
Already the similarity between computers and living things is striking.
Everything that we are is written down in a book of sorts.
The
writing of this book employs a real alphabet and a real language.
So far, the only difference between the genetic code of humans and the
binary code of computers is the difference in the number of letters used.
We have four letters while computers have only two letters  to work with.
The only difference here is that more letters enable greater information
compaction. However, both alphabets
can be set up to code for the same information without any change to the clarity
of that information. As long as the
reader of the information understands the code or language that the alphabet is
written in, the information itself need not be changed.
to work with.
The only difference here is that more letters enable greater information
compaction. However, both alphabets
can be set up to code for the same information without any change to the clarity
of that information. As long as the
reader of the information understands the code or language that the alphabet is
written in, the information itself need not be changed.
Since the basic language or code of life is so similar to the basic language or code of computer systems, it seems quite logical that one could be used to simulate the other. In fact, scientists have recently created DNA computers that actually work based on the four letters in our own genetic alphabet. Likewise, scientists have also used computers to simulate organic life, reproduction, and evolution. Many of these computer simulations look impressive indeed. But are these computer animations really growing, changing, or evolving?
In this line, a recent and very interesting paper was published by Lenski et. al., entitled, "The Evolutionary Origin of Complex Features" in the 2003 May issue of Nature. In this particular experiment the researchers studied 50 different populations, or genomes, of 3,600 individuals. Each individual began with 50 lines of code and no ability to perform "logic operations". Those that evolved the ability to perform logic operations were rewarded, and the rewards were larger for operations that were "more complex". After 15,873 generations, 23 of the genomes yielded descendants capable of carrying out the most complex logic operation: taking two inputs and determining if they are equivalent (the "EQU" function). The lines of code that made up these individuals ranged from 49 to 356 instructions long. The ultimately dominant type of individual contained 83 instructions and the ability to perform all nine logic functions that allowed it to gain more computer time.
In principle, 16 mutations (recombinations) coupled with the three instructions that were present in the original digital ancestor could have combined to produce an organism that was able to perform the complex equivalence operation. What actually happened was a bit more complicated. The equivalence operation function evolved after 51 to 721 steps along the evolutionary path, and the "organisms" used anywhere from 17 to 43 instructions to carry it out. The most efficient of the evolved equivalence functions was just 17 lines of code - two fewer than the most efficient code the researchers had come up with beforehand. Evolving even as few as 17 lines required a few more than 16 recombination/mutation events (but not that many really, considering that the majority of these "mutations" were functional). In one case, 27 of the 35 instructions that an organism used to perform the logic operation were derived through recombination, and all but one of them had appeared in the line of descent before the complex function was performed.
The researchers' model involved 103 single mutations/recombinations, six double mutations, and a pair of triple mutations. In the short-term 45 of those were beneficial, 48 neutral, and 18 detrimental. Thirteen of the 45 beneficial steps gave rise to logic functions not expressed by the immediate parent. Fifteen of the 18 detrimental mutations made the offspring slightly less fit, or likely to propagate, than the parent. Two of the detrimental mutations cut in half the offspring's fitness. One of these very detrimental mutations, however, did produce offspring that one step later produced a mutation that in turn gave rise to the complex logic operation.
This all looks very much like the evolution of complex software functions in computer code and many are quite convinced that the parallel is very close to what happens in the natural world. However, there are several interesting constraints to this experiment. For one thing, the ultimate functional goal was predetermined as with Dawkins's "Methinks it is like a weasel" computer evolution experiment - except that there was a difference here in that each of the steps involved with Lenski's experiment were actually functionally unique. The problem is that these functions were predetermined by intelligent design to be functionally beneficial. Basically, the proper environment was a set-up for the success of a particular evolutionary scenario, which was already pre-determined via intelligent design. Also, the types of mutations that were used were not generally point mutations, but were based on swapping large sections of pre-programmed meaningful bit code around. The researchers knew that with a relatively few recombinations of code such a logic function of "increasing complexity" would be realized. After all, the environment was set up to produce changes were the ratio of beneficial changes as compared to all other potential changes was very high. Like the evolution of antibiotic resistance this function was easy to evolve given the restraints used by the scientists because the neutral gaps were set up to be so small. Also, the success of the experiment was dependent on pre-established lines of code that were set up to work together to solve logical problems of a specific type.
I suggest however that this particular setup would not be able to evolve other types of functions, like the ability to open the CD-drive or the ability to cause the monitor to blink off and on. The gaps involved would require different types of starting code sequences that could not be gained by the type of code recombination used in this experiment. Point mutations would be required and very large gaps in function would need to be crossed before these other functions could be realized.
In short, I think that this experiment was a setup for the success of a very limited goal and does not explain the evolution of uniquely functional systems beyond the most elementary of levels. It did end up producing some "unexpected" solutions to the problem, but that is only to be expected. There might be many different ways to interfere with an antibiotic's interaction with a target sequence that might not be otherwise expected. However, the functional ratio is what is important here and clearly it is very high as compared to the neutral sequences (40% beneficial mutations vs. 10% detrimental and only 43% neutral - Please! Give me a break!). Success was guaranteed by the way the intelligent designers set up their experiment. They were able to sequentially define their own environment ahead of time in a very specified way. The logic functions that were evolved were dependent upon the proper selective environment being set up ahead of time by ID. What if there was a gap between one type of logic function and another type of logic function? - such as between the NAND and the EQU functions that required the evolution of either the AND or the OR, or the NOR, XOR or NOT functions first? What if these functions were not recognized by a particular environment as being beneficial? Then, there would be a neutral gap created by that environment between the NAND and EQU functions. What are the odds that the "proper" environment that recognized at least one of these other functions as beneficial, would come around at the right time?
You see, the random walk not only includes random changes in code, but also in environment. Without an intelligent mind directing changes in environment in just the proper way, the organic synthesis of many different compounds that are made in chemistry laboratories would not work. The order of the environmental changes is just as important as the order of the molecules in the "evolution" of new functions or compounds.
Interestingly
enough, Lenski and the other scientists thought of this potentiality themselves,
so they set up different environments to see which environements would support
the evolution of all the potentially beneficial functions - to include the most
complex EQU function. Consider the following description about what
happened when various intermediate steps were not arbitrarily defined by the
scientists as "beneficial".
"At the other extreme, 50 populations evolved in an environment where only EQU was rewarded, and no simpler function yielded energy. We expected that EQU would evolve much less often because selection would not preserve the simpler functions that provide foundations to build more complex features. Indeed, none of these populations evolved EQU, a highly significant difference from the fraction that did so in the reward-all environment (P = 4.3 x 10e-9, Fisher's exact test). However, these populations tested more genotypes, on average, than did those in the reward-all environment (2.15 x 10e7 versus 1.22 x 107; P<0.0001, Mann-Witney test), because they tended to have smaller genomes, faster generations, and thus turn over more quickly. However, all populations explored only a tiny fraction of the total genotypic space. Given the ancestral genome of length 50 and 26 possible instructions at each site, there are ~5.6 x 10e70 genotypes; and even this number underestimates the genotypic space because length evolves."
Isn't that just fascinating? When the intermediate stepping stone functions were removed, the neutral gap that was created successfully blocked the evolution of the EQU function. Now, isn't this consistent with my predictions? This experiment was successful because the intelligent designers were capable to defining what sequences or functions were "beneficial" for their evolving "organisms." If enough sequences or functions are defined as beneficial, then certainly such a high ratio will result in rapid evolution - as we saw here. However, when neutral non-defined gaps are present, they are a real problem for evolution. In this case, a gap of just 16 neutral mutations effectively blocked the evolution of the EQU function. (Just for those who are curious, listed with the references are the detailed "Experimental Conditions" listed by the authors).
The problem here is that without the input of higher information from the intelligent minds of the scientists, this experiment would have failed. All specified systems of function of increasing complexity require the input of some sort of higher pre-established source of information - be that information stored in the form of a genetic code or a human scientist. The reason for this is that left to themselves, the individual parts simply do not know how to arrange themselves in any particular orientation with other parts to create a specified function of high complexity. Because of this, the best that the parts themselves can self-assemble, without the aid of a higher source of information, is a homogenous ooze or a homogenous crystalline structure.
Many people think that all changes in function are equal - that just any example of evolution in action can explain all other differences in function. The fact is that there are different levels of functional complexity. Some changes are much easier to achieve than others. But all change costs something. This price is called "entropy." The entropy of a system is a description of that system's ability to do useful work. In other words, it is a description of non-equilibrium or non-homogeny. For example, consider two boxes A and B. Both boxes contain gas molecules. The molecules in box B are hotter and therefore move faster. If allowed to mix, the disequilibrium creates a gradient that can be used to perform useful work. For example, the motion of the gas from box B to box A could be used to turn a fan and create electrical energy. However, when equilibrium is reached, the fan will no longer turn. At equilibrium, the entropy of this system is said to be at it's maximum. Statistically, it is possible for the gas molecules, by some random chance coincidence, to happen to bounce around just right so that they all end up back in box B, turning the fan as they go. This is in fact possible, but is it probable? Entropy is therefore a description of work probability. A drop of water from a fishbowl might organize its molecular energy so that it stands up and walks right out of the fish bowl and jumps down onto the table below. This event is statistically possible but it is very improbable that the molecules in that particular drop of water would just happen to act together in such a fashion - according to the laws of entropy.
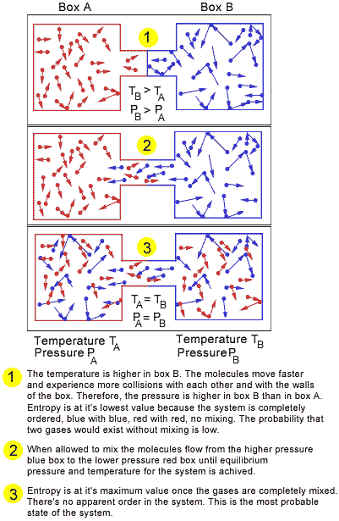 So,
according to the law of entropy, all mindless natural changes tend toward
equilibrium - or the lowest state of probable work potential. How then do
living things seem to buck the system? Living systems strive to maintain
disequilibrium or a low state of entropy. Living systems move and work
constantly without loosing the ability to work. In fact they often
increase their ability to work the more that they work. Does this not go
directly against a fundamental law of nature? It would seems that they do
except for the fact that the work done by living things comes at an entropic
cost to the surrounding environment or "system." The entropy of
the universe increases every time you scratch your ear or blink your eyes.
However, when a living thing dies, it no longer maintains itself in
disequilibrium. It can no longer buck the law of entropy. The
building blocks of the living system immediately begin to fall back into
equilibrium with each other to form a homogenous ooze. Living systems are
fairly unique in that they are consistently able to take this same homogenized
ooze and use it to form nonhomogenized systems capable of work. How do
living systems do this? They are programmed to do this with a pre-existing
code of information much like computers are programmed to buck entropy.
So,
according to the law of entropy, all mindless natural changes tend toward
equilibrium - or the lowest state of probable work potential. How then do
living things seem to buck the system? Living systems strive to maintain
disequilibrium or a low state of entropy. Living systems move and work
constantly without loosing the ability to work. In fact they often
increase their ability to work the more that they work. Does this not go
directly against a fundamental law of nature? It would seems that they do
except for the fact that the work done by living things comes at an entropic
cost to the surrounding environment or "system." The entropy of
the universe increases every time you scratch your ear or blink your eyes.
However, when a living thing dies, it no longer maintains itself in
disequilibrium. It can no longer buck the law of entropy. The
building blocks of the living system immediately begin to fall back into
equilibrium with each other to form a homogenous ooze. Living systems are
fairly unique in that they are consistently able to take this same homogenized
ooze and use it to form nonhomogenized systems capable of work. How do
living systems do this? They are programmed to do this with a pre-existing
code of information much like computers are programmed to buck entropy.
Computers create non-homogeny just like living systems do. They create order out of apparent chaos. They can be programmed to organize disordered (homogenized) building blocks so that they will have a working function. Of course there are many different types of workable systems that could be created given a particular set of building blocks. The same building blocks could be used to build a house or a car. Computers do not know this however. They are programmed to use the building blocks to build only what they are told to build. The same is true for living systems. Living things build only what their DNA tells them to build. The fact is that the same basic building blocks are used in all living things, but the individual cell only knows what its DNA tells it. Once specialized, a single cell in the toe of a turtle only knows how to use the building blocks to make turtle toe parts. The question of course is, can computers or living things build ordered systems that go uniquely beyond or outside of their original programming?
No one questions the idea that change happens. Change is obvious. However, can a mindless natural law process that always tends toward equilibrium end up working against itself by contributing to the establishment of new and unique ways of reducing equilibrium? Is there any known natural law process that would upgrade a computer's software and or hardware outside of intelligent human creativity? We do know that the genetic make-up (software) of all creatures does in fact "change." The "software" programs of living things do in fact change. How does this happen? These changes are surprisingly not part of the software package itself. These changes are apparent accidents. They are not based on the normal functions of life, but in the normal functions of natural law. These natural law changes are referred to as "random mutations" in the software of living things. If allowed to continue unchecked, these mutations tend toward non-functional homogeny. By themselves, these mutations can in fact increase the specified order or functional complexity of the software package - but only in the most limited way. In the same way a few molecules of water in a river may run uphill for a while, but not for very long and not in any significant way. Why is this? Because they follow the natural law of entropy. Mutations in any system generally tend toward random homogeny, disorder, nonfunction, or an inability to work. Rarely one or two mutations may happen to come across a new and beneficial function of increasing complexity - but always these new functions are from the lowest levels of functional complexity. For example, although very simple functions like antibiotic resistance and even the evolution of unique single protein enzymes (like the lactase or nylonase enzymes) have been shown to evolve in real time, no function on the higher level of a multi-protein system where each protein works together at the same time in a specified orientation to the other proteins has been observed to evolve. Such multi-protein part systems are everywhere, to include such systems as bacterial motility systems (like the flagellum) and yet not one of them has been observed to evolve - period. Just like the drop of water walking out of the fish bowl, it is statistically possible for hypermutation to create new and amazing systems of function of very high complexity, but it just never happens beyond the lowest levels of functional complexity. Hypermutation follows the laws of increasing entropy just like the gas molecules in boxes A and B until equilibrium is reached. Death is the ultimate end of hypermutation. No living thing can tolerate hypermutation for very long.
But, natural selection is supposed to come to the rescue - but does it? Natural selection is a process where nature selects those software changes that produce more durable and reproducible hardware given a particular environment and discards the ones that do not. In this way, the random mutations that would otherwise lead to homogeny are manipulated by the guiding force of natural selection toward a diversity of functions that go farther and still farther away from homogeny. Natural selection is supposed to be an amazing power. It is supposed to be able to subvert a fundamental law of nature by turning meaningless non-working, non-functional, homogenous ooze into more and still more diversely working systems. How does natural selection do this? Natural selection is said to rely on statistical probability. For example, lets say that only one out of a million random software changes or mutations is beneficial. If this benefit is detectable by nature, or any other selecting force, then things can be improved over time. The statistics of random chance, when combined with a selective force, are bent in favor of higher order instead of disorder. The question then arises, if natural selection works so well for the improvement of the software of living things, then why not use it to improve computer software as well? This question does seem reasonable since both kinds of systems us a similar coded language. If natural selection works with one alphabet, it should just as easily be able to work with the other alphabet. And yet, this has not happened with either computers or the "software" of living things beyond the lowest levels of functional complexity. Why not?
It turns out that natural selection cannot read the coded language of computers or living things. Natural selection does not see the alphabets of either system. Natural selection is only capable of selecting hardware changes or changes in hardware function. But isn't hardware function based in the software and wouldn't changes to the software change hardware function? Yes and no. Hardware function is completely based in the software, but this basis is dependent upon a specified arrangement of parts. Not all arrangements will have the same function, much less any beneficial function at all. Sometimes the functional meaning of a particular part is quite arbitrary - just as the meaning of a word is arbitrarily attached to a series of symbols called letters. Without this arbitrary attachment, the letters themselves mean nothing and have no function. The same is true for bit and bytes in a computer and for the genetic code in living things. So, if the symbols change or get mutated to something that does not have a meaning or a function arbitrarily attached to them, then there is no recognized function. There is no expressed phenotype. Without a phenotype, they are invisible to the process of natural selection. All subsequent changes to their underlying code are "neutral" and from here on out are dependent upon laws of random chance alone. This always leads to lifeless homogeny. So, what are the odds that random chance will buck the law of increasing entropy and "work"? What are the odds that the drop of water will dance out of the fish bowl?
Still not convinced? Lets take a closer look into the languages of computers and living things. Computer language is set up using a system of "bits" and "bytes." A bit is either a zero or a one. Eight bits in a series is a byte. For example, the series 10101010 is a byte. If a bit is comparable to a letter in the English language, then a byte is comparable to a word. The computer assigns various meanings to the "byte words." This assignment of meaning or function is arbitrary, as it is in any symbolic language (and as it was with the Lenski experiment where various functions were arbitrarily defined as being "beneficial"). The same thing happens with genetic words in living systems. Therefore, a single byte could be assigned an alphanumeric "meaning" such as the letter "A." For a series of eight bits, there are 256 different possible combinations. This means that a computer byte could represent up to 256 separate defined functions. Each of these words would have to have a separate recognized definition in the computer's arbitrary dictionary of words.
 The
same is true for any living system. Every
genetic word in DNA has an arbitrary definition assigned to it by the "genetic
code." However, instead of
The
same is true for any living system. Every
genetic word in DNA has an arbitrary definition assigned to it by the "genetic
code." However, instead of
So, if a computer’s code gave a separate functional definition to each one of 256 possible bytes in its dictionary, a single change in any given byte would yield a detectable change in function. If this change was a desired change, it could be kept while other changes could be discarded. Evolution would be a simple and relatively quick process. The problem is that a computer needs more than 256 separate functions and even the simplest living system needs far more than 64 separate functions. How are these needs met? What if multiple words are used to code for other unique definitions? What if two bytes were joined together and given a completely unique definition by the computer? How many possible functions would there be now? There would be 65,536 different possible defined functions that could be recognized in the computer’s dictionary.
 This
is in fact what happens. Computer
codes assign arbitrary meaning to multiple bytes.
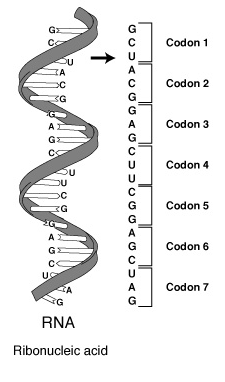
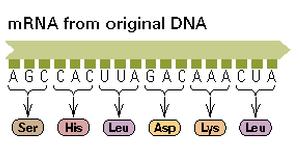
Likewise, the DNA language of living systems is translated into another
language of living systems called proteins.
The protein language is based on an alphabet of 20 letters called amino
acids.1 A protein is put
together in linear order as dictated by a linear codon sequence in the DNA.
This protein can be very long, hundreds or even thousands of amino acid
"letters" long and yet it is assigned an arbitrary meaning by the
particular system that it "fits" in with.
Because of the vast number of possible proteins of a given length, not
every protein has a defined or beneficial function in a given life form or
system of function as it acts in a particular environment.
Of course, this means that not every change in DNA and therefore protein
sequencing will result in a beneficial change in system function.
The same is true for computers. Because
of the combination of defined bytes in computer language, some of the possible
bytes or byte combinations will not be defined as "beneficial".
If these happen to “evolve” by random mutation, they will not yield a
change up the ladder of functional complexity.
This
is in fact what happens. Computer
codes assign arbitrary meaning to multiple bytes.
Likewise, the DNA language of living systems is translated into another
language of living systems called proteins.
The protein language is based on an alphabet of 20 letters called amino
acids.1 A protein is put
together in linear order as dictated by a linear codon sequence in the DNA.
This protein can be very long, hundreds or even thousands of amino acid
"letters" long and yet it is assigned an arbitrary meaning by the
particular system that it "fits" in with.
Because of the vast number of possible proteins of a given length, not
every protein has a defined or beneficial function in a given life form or
system of function as it acts in a particular environment.
Of course, this means that not every change in DNA and therefore protein
sequencing will result in a beneficial change in system function.
The same is true for computers. Because
of the combination of defined bytes in computer language, some of the possible
bytes or byte combinations will not be defined as "beneficial".
If these happen to “evolve” by random mutation, they will not yield a
change up the ladder of functional complexity.
To illustrate this point consider that in living systems each of 64 codons code for one of only 20 amino acids. We can now draw a parallel and imagine a computer where the 256 bytes each code for one of the 26 letters of the English alphabet, a space, and a period to make only 28 possible characters. Now, lets imagine a computer that defines functions according to English words or phrases averaging 28 characters in length. How many different functional definitions would be available to this computer? The answer is quite huge at 3 x 1040. To help one understand this number, the human genome contains only about 35,000 genes.2 That means that to create a completely functional human, it takes less than 35,000 uniquely defined proteins. This is on the very small side of what is possible for recognized proteins. If a given function required just one protein averaging only 100 amino acids in length there would be 1 x 10130 different potential proteins that could be used (That is a 1 with 130 zeros after it). However, human "systems" only recognize the smallest fraction out of all these possibilities. The same is true for computer systems.
Lets say then that our computer recognizes 1,000,000 separate written commands of a level of function that averages 28 English characters in length. Starting with one recognized command, how long would it take to "evolve" any other recognized command at that level of function if a unique command was tried each and every second? You see the initial problem? It is one of recognition. If the one recognized word is changed, it will no longer be recognized. It will be functionless. Without recognized function, there is no guidance or driving force in any future word changes. The changes from here on out are strictly dependent upon random chance alone (so called "neutral" evolution). The statistics of random walk say that on average it would take 3 x 1026 years or one hundred trillion trillion years to arrive at another word that is recognized or "functional." Without a functional pathway each and every step of the way, this neutral gap blocks the power of natural selection to select and therefore this gap blocks the change of one beneficial phrase into any other beneficial phrase of a particular level of complexity.
So far, computers have not been able to evolve their own software beyond the most simple levels of function (as described above) without the help of intelligent design from computer scientists. Computers are always dependent upon outside programming for any changes in function that go up the ladder of complexity beyond the lowest levels of functional complexity. A computer, as of today, cannot evolve brand new software programs or do much of anything beyond its original programming. Why? Because, if the selector can only select based on function, then, as one moves up the ladder of functional complexity, the selector will soon be blinded by gaps of neutral changes in the underlying code which give the selector no clue that the changes have even taken place much less which changes are "better" or "worse" than any other "neutral" change.
I propose that the same problems hold true when it comes to Darwinian-style evolution in living things. Nature can only select based on what it sees. What nature sees is function - not the underlying language code or molecular symbols in the DNA itself. The statistical gaps between the recognized words in a living system’s dictionary are huge. The gaps are so huge that, to date, the best evolutionary evidence demonstrated in the lab describes changes separated by only one, two or possibly three amino acid "letter" changes.3 Without experiments or good statistical arguments to explain these problems, evolutionary theories are in serious trouble when they try to explain the existence of complex computer or biological functions that rise above the lowest rungs on the ladder of specified functional complexity.
1.
Gelehrter, Thomas D. et al. Principles
of Medical Genetics, 1998.
2.
Lemonick, M. Gene Mapper,
Time, Vol. 156, No. 26, pp110, 2001.
3. B.G. Hall, Evolution on a Petri Dish. The Evolved B-Galactosidase System as a Model for Studying Acquisitive Evolution in the Laboratory, Evolutionary Biology, 15(1982): 85-150.
4. Lenski, Richard, Ofria, Charles, Pennock, Robert and Adami, Christoph. "The evolutionary origin of complex features." Nature, 8 May 2003, vol. 423, p.130.
"Avida software was used. Every population started with 3,600 identical copies of an ancestral genotype that could replicate but could not perform any logic functions. Each replicate population that evolved in the same environment was seeded with a different random number. The hand-written ancestral genome was 50 instructions long, of which 15 were required for efficient self-replication; the other 35 were tandem copies of a single no-operation instruction (nop-C) that performed no function when executed. Copy errors caused point mutations, in which an existing instruction was replaced by any other (all with equal probability), at a rate of 0.0025 errors per instruction copied. Single-instruction deletions and insertions also occurred, each with a probability of 0.05 per genome copied. Hence, in the ancestral genome of length 50, 0.225 mutations are expected, on average, per replication. Various organisms from nature have genomic mutation rates higher or lower than this value. Mutations in Avida also occasionally cause the asymmetrical division of copied genome, leading to the deletion or duplication of multiple instructions. Each digital organism obtained 'energy' in the form of SIPs at a relative rate (standardized by the total demand of all organisms in the population) equal to the product of its genome length and computational merit, where the latter is the product of rewards for logic functions performed. The exponential reward structure shown was used in the reward-all environments, whereas some functions obtained no reward under other regimes. An organism's expected reproductive rate, or fitness, equals its rate of energy acquisition divided by the amount of energy needed to reproduce. Fitness can also be decomposed into replication efficiency (ratio of genome length to energy required for replication) and computational merit. Each population evolved for 100,000 updates, an arbitrary time unit equal to the execution of 30 instructions, on average, per organism. The ancestor used 189 SIPs to produce an offspring, so each run lasted for 15,873 ancestral generations. Populations existed on a lattice with a capacity of 3,600 individuals. When an organism copied its genome and divided, the resulting offspring was randomly placed in one of the eight adjacent cells or in the parent's cell. Each birth caused the death of the individual that was replaced, thus maintaining a constant population size."
. Home Page . Truth, the Scientific Method, and Evolution
.
. Maquiziliducks - The Language of Evolution . Defining Evolution
.
.
Evolving
the Irreducible
.
.
.
.
.
. DNA Mutation Rates . Donkeys, Horses, Mules and Evolution
.
.
. Amino Acid Racemization Dating . The Steppingstone Problem
.
.
Since June 1, 2002
The Density of Beneficial Functions
All Functions are Irreducibly Complex
Confusing Chaos with Complexity
Scientific Theory of Intelligent Design
The Limits of Functional Flexibility
Functions based on Deregulation
Links to Design, Creation, and Evolution Websites
Since June 1, 2002